著者はハードウェアに強い関心を持ち、JMeterを用いて負荷テストを実施し、CentOS 7上にJMeter、InfluxDB、Grafanaをデプロイするプロセスを記録しました。JMeterのインストールとコマンドの使用方法、InfluxDBの特徴とDockerによるインストール方法、Grafanaの簡易的なデプロイと設定について共有しています。高性能プログラムモードに関する経験や参考資料をまとめました。
背景
広く知られているように、私にはハードウェアに対する強い関心が持っており、テストグループが JMeter を使用して負荷テストを行っている際に、パフォーマンスが向上しないことを発見しました。好奇心旺盛な私は、会社の負荷テストの方法を試してみることに決意しました。また、ある頃合いにオープンソース中国で、より洗練された高性能のパフォーマンス測定グラフを作成する方法に関する投稿を読んだことがあります。Windows版でのテスト実行時に、可視化された TPS データの表示を実現しており、Webパネルを設定することでどのような効果があるのか疑問に思っていました。
頭の中で思いついたのは、当然のことばかりです。実際に試してみないとしかたないことを理解します。 負荷テストには GUI モードを使用しないでください! テスト作成とデバッグのみに使用してください。
背景
公式推奨は、コマンドラインで負荷テストレポートを取得し、GUIで表示する方法ですが、データに誤差が含まれているという問題があります。JMeterの理解が十分ではないため、少なくともLinux版のコンソールパネルを弄り転げる理由を見つけたいと思います。
開かれた中国(オープンチャイナ)の投稿では、コアコンポーネントのデプロイメント方法があまりにも友好的ではなく、インストールに必要なファイルは公众号を通じてダウンロードする必要があり、現代的な若者として、もちろんDockerで代替します。要するに、サーバーは国内であり、国境を越えたソースアドレスへのアクセス速度が遅いため、少なくともイメージサービスとしては、阿里云には無料の加速があります。
docker のインストールとデプロイメントについては、ここでは詳細な説明を省略し、以前の記事を参照してください。
次の内容は、2つの主要な領域に分かれています:基本的なテスト環境コンポーネントの構築、および各コンポーネントの簡単な認識の説明
JMeter
Apache JMeterはApache組織が開発したJavaベースの負荷テストツールです。ソフトウェアに対する負荷テストに使用され、当初はWebアプリケーションのテスト用に設計されましたが、その後、他のテスト分野にも拡張されています。静的および動的なリソース(静的ファイル、Java小型サービスプログラム、CGIスクリプト、Javaオブジェクト、データベース、FTPサーバーなど)をテストするために使用できます。JMeterは、さまざまな負荷カテゴリからの巨大な負荷をシミュレートして、それらの強度をテストし、全体的なパフォーマンスを分析するために使用できます。さらに、JMeterはアプリケーションの機能/回帰テストに使用でき、断言を含むスクリプトを作成することで、プログラムが期待どおりの結果を返していることを検証します。最大限の柔軟性のため、JMeterは正規表現を使用して断言を作成することを許可しています。
Apache jmeter は、静的および動的なリソース(ファイル、Servlet、Perlスクリプト、Java オブジェクト、データベースとクエリ、FTPサーバーなど)のパフォーマンスをテストするために使用できます。 サーバー、ネットワーク、またはオブジェクトに過剰な負荷をシミュレートして、それらの強度をテストしたり、さまざまなストレスタイプの下での全体的なパフォーマンスを分析したりすることができます。 大規模な同時負荷テストでサーバー/スクリプト/オブジェクトのパフォーマンスを分析したり、グラフィカルなパフォーマンス分析を行ったりするために使用できます。
Jmeter 導入 CentOS7
JDK の実行環境をインストールし、JMeter のインストールパッケージをダウンロードします。
yum install java-1.8.0-openjdk -y && \
wget https://mirrors.bfsu.edu.cn/apache//jmeter/binaries/apache-jmeter-5.4.tgz && tar -xf apache-jmeter-5.4.tgz
環境変数を設定します。
export JMETER_HOME=$HOME/jmeter/apache-jmeter-5.4
export PATH=$JMETER_HOME/bin:$PATH
JMeter コマンド
最後に Grafana ダッシュボードに送信し、-l パラメータを入力しなくても、web コンソールでデータを観察できます。
jmeter -n -t /tmp/order-500-10s.jmx -l /tmp/jmeter-order-report-20200109/order-500-10s.jtl
# 通常、テスト結果とテストレポートは省略し、コマンドを簡略化します。
jmeter -n -t /tmp/order-500-10s.jmx
InfluxDB
InfluxDBは、Go言語で記述されたオープンソースの分散型時系列、イベント、指標データベースです。外部依存なしで動作します。このデータベースは現在、大量の時間スタンプデータ(DevOpsモニタリングデータ、APPメトリクス、IoTセンサーデータ、リアルタイム分析データなど)を保存するために主に利用されています。
InfluxDBの特徴
InfluxDBの特徴は、以下の9点にまとめられます。
- 非構造化(非モデリング):任意の数の列を含めることができます。
- メトリクスの保存期間を設定できます。
- 時間に関連する関数(min、max、sum、count、mean、medianなど)をサポートし、統計分析が容易です。
- ストアポリシーのサポート:データの削除および変更に使用できます。(InfluxDBはデータの削除と変更の方法を提供していません。)
- 連続クエリのサポート:データベース内で自動的にスケジュールされたステートメントのセットであり、ストアポリシーと組み合わせてInfluxDBのシステム使用量を削減できます。
- ネイティブなHTTPサポート、組み込みHTTP API。
- SQLライクな構文をサポート。
- クラスタ内のデータのレプリカ数を設定できます。
- 定期的なサンプリングデータによる別の測定項目の書き込みをサポートし、粒度ごとのデータを保存できます。
InfluxDB Docker インストール
mkdir influxdb && cd influxdb && \
docker run -p 8086:8086 -d --name influxdb -v $PWD:/var/lib/influxdb influxdb:1.7
docker exec -it influxdb /bin/bash でコンテナに入り、コマンドを実行し、手動でデータベースを作成
root@bce0a55bbc72:/# influx
http://localhost:8086 への接続、バージョン 1.7.10
InfluxDB シェル バージョン:1.7.10
> 対話式パネルでコマンドを実行
InfluxDBデータベースとユーザーの作成
データベースの作成: create database jmeter_t2
データベースの表示: show databases
データベースの切り替え: use jmeter_t2
ユーザーの作成: create user "admin" with password 'admin' with all privileges
ユーザーの表示: show users
> show users
user admin
---- -----
admin true
ユーザー権限がadminでtrueと表示されれば、データベースの準備は完了です。
Grafana
テストケースの作成時に、グラフによる表現はあまり必要ないことがわかりました。インターフェースの tps データのコマンドライン実行で十分観測できます。むしろ、プログラム内部の処理時間を確認したいと考えています。
Grafana の簡易的なコンソールパネルをデプロイし、InfluxDB と連携するための設定ファイルをインポートします。
コンソールはラベルによるフィルタリングをサポートしており、通常は 1 つの InfluxDB データベースを設定するだけで済みます:
- アプリケーション名
- テストケース名
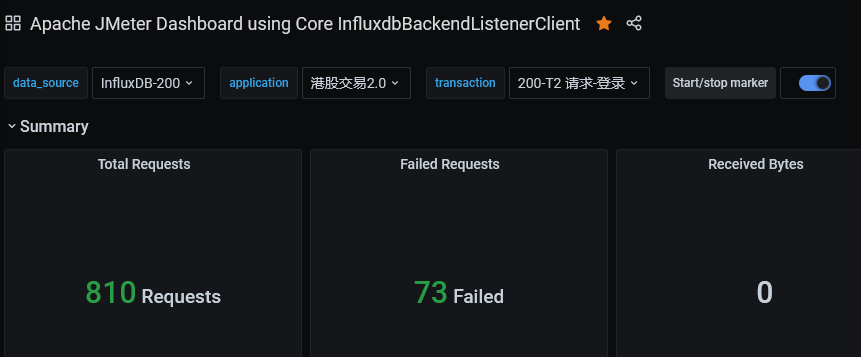
docker run -d --name=grafana -p 3000:3000 grafana/grafana:7.3.1
ブラウザ版ではサンプリング間隔により、計算された TPS や関連数値が JMeter の集計レポートと一致しないため、参照リンク:https://www.vinsguru.com/jmeter-real-time-results-influxdb-grafana/ を参考にしています。
資料には、リスナーのカスタム設定方法も記載されています。
付録
- 高性能のプログラムパターンは、必然的にone loop threadであるべきであり、ロック、入隊列、出隊列などのものは、不必要なパフォーマンス損失を引き起こす
- 核心ビジネスロジックの実行時間が、他のコードを導入する時間よりも大きい場合のみ、並行処理が有効に効率を向上させることができ、コアな実行時間が十分に小さい場合は、慎重に他のコードを導入すべき